Using pre-trained models in ASE#
First, install
fairchemin a fresh python environment using one of the approaches in installation documentation.See what pre-trained potentials are available
from fairchem.core.models.model_registry import available_pretrained_models
print(available_pretrained_models)
('CGCNN-S2EF-OC20-200k', 'CGCNN-S2EF-OC20-2M', 'CGCNN-S2EF-OC20-20M', 'CGCNN-S2EF-OC20-All', 'DimeNet-S2EF-OC20-200k', 'DimeNet-S2EF-OC20-2M', 'SchNet-S2EF-OC20-200k', 'SchNet-S2EF-OC20-2M', 'SchNet-S2EF-OC20-20M', 'SchNet-S2EF-OC20-All', 'DimeNet++-S2EF-OC20-200k', 'DimeNet++-S2EF-OC20-2M', 'DimeNet++-S2EF-OC20-20M', 'DimeNet++-S2EF-OC20-All', 'SpinConv-S2EF-OC20-2M', 'SpinConv-S2EF-OC20-All', 'GemNet-dT-S2EF-OC20-2M', 'GemNet-dT-S2EF-OC20-All', 'PaiNN-S2EF-OC20-All', 'GemNet-OC-S2EF-OC20-2M', 'GemNet-OC-S2EF-OC20-All', 'GemNet-OC-S2EF-OC20-All+MD', 'GemNet-OC-Large-S2EF-OC20-All+MD', 'SCN-S2EF-OC20-2M', 'SCN-t4-b2-S2EF-OC20-2M', 'SCN-S2EF-OC20-All+MD', 'eSCN-L4-M2-Lay12-S2EF-OC20-2M', 'eSCN-L6-M2-Lay12-S2EF-OC20-2M', 'eSCN-L6-M2-Lay12-S2EF-OC20-All+MD', 'eSCN-L6-M3-Lay20-S2EF-OC20-All+MD', 'EquiformerV2-83M-S2EF-OC20-2M', 'EquiformerV2-31M-S2EF-OC20-All+MD', 'EquiformerV2-153M-S2EF-OC20-All+MD', 'SchNet-S2EF-force-only-OC20-All', 'DimeNet++-force-only-OC20-All', 'DimeNet++-Large-S2EF-force-only-OC20-All', 'DimeNet++-S2EF-force-only-OC20-20M+Rattled', 'DimeNet++-S2EF-force-only-OC20-20M+MD', 'CGCNN-IS2RE-OC20-10k', 'CGCNN-IS2RE-OC20-100k', 'CGCNN-IS2RE-OC20-All', 'DimeNet-IS2RE-OC20-10k', 'DimeNet-IS2RE-OC20-100k', 'DimeNet-IS2RE-OC20-all', 'SchNet-IS2RE-OC20-10k', 'SchNet-IS2RE-OC20-100k', 'SchNet-IS2RE-OC20-All', 'DimeNet++-IS2RE-OC20-10k', 'DimeNet++-IS2RE-OC20-100k', 'DimeNet++-IS2RE-OC20-All', 'PaiNN-IS2RE-OC20-All', 'GemNet-dT-S2EFS-OC22', 'GemNet-OC-S2EFS-OC22', 'GemNet-OC-S2EFS-OC20+OC22', 'GemNet-OC-S2EFS-nsn-OC20+OC22', 'GemNet-OC-S2EFS-OC20->OC22', 'EquiformerV2-lE4-lF100-S2EFS-OC22', 'SchNet-S2EF-ODAC', 'DimeNet++-S2EF-ODAC', 'PaiNN-S2EF-ODAC', 'GemNet-OC-S2EF-ODAC', 'eSCN-S2EF-ODAC', 'EquiformerV2-S2EF-ODAC', 'EquiformerV2-Large-S2EF-ODAC', 'Gemnet-OC-IS2RE-ODAC', 'eSCN-IS2RE-ODAC', 'EquiformerV2-IS2RE-ODAC')
Choose a checkpoint you want to use and download it automatically! We’ll use the GemNet-OC potential, trained on both the OC20 and OC22 datasets.
from fairchem.core.models.model_registry import model_name_to_local_file
checkpoint_path = model_name_to_local_file('GemNet-OC-S2EFS-OC20+OC22', local_cache='/tmp/fairchem_checkpoints/')
checkpoint_path
'/tmp/fairchem_checkpoints/gnoc_oc22_oc20_all_s2ef.pt'
Finally, use this checkpoint in an ASE calculator for a simple relaxation!
from fairchem.core.common.relaxation.ase_utils import OCPCalculator
from ase.build import fcc111, add_adsorbate
from ase.optimize import BFGS
import matplotlib.pyplot as plt
from ase.visualize.plot import plot_atoms
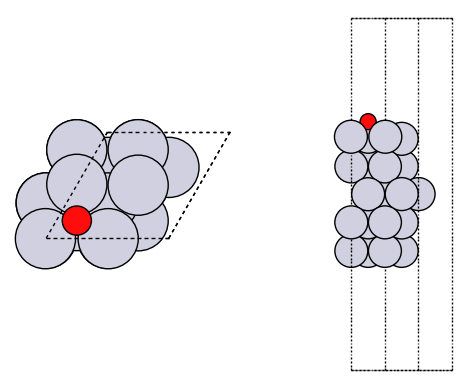
# Define the model atomic system, a Pt(111) slab with an *O adsorbate!
slab = fcc111('Pt', size=(2, 2, 5), vacuum=10.0)
add_adsorbate(slab, 'O', height=1.2, position='fcc')
# Load the pre-trained checkpoint!
calc = OCPCalculator(checkpoint_path=checkpoint_path, cpu=False)
slab.set_calculator(calc)
# Run the optimization!
opt = BFGS(slab)
opt.run(fmax=0.05, steps=100)
# Visualize the result!
fig, axs = plt.subplots(1, 2)
plot_atoms(slab, axs[0]);
plot_atoms(slab, axs[1], rotation=('-90x'))
axs[0].set_axis_off()
axs[1].set_axis_off()
/home/runner/work/fairchem/fairchem/src/fairchem/core/models/scn/spherical_harmonics.py:23: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
_Jd = torch.load(os.path.join(os.path.dirname(__file__), "Jd.pt"))
/home/runner/work/fairchem/fairchem/src/fairchem/core/models/equiformer_v2/wigner.py:10: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
_Jd = torch.load(os.path.join(os.path.dirname(__file__), "Jd.pt"))
/home/runner/work/fairchem/fairchem/src/fairchem/core/models/escn/so3.py:23: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
_Jd = torch.load(os.path.join(os.path.dirname(__file__), "Jd.pt"))
/home/runner/work/fairchem/fairchem/src/fairchem/core/common/relaxation/ase_utils.py:191: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
checkpoint = torch.load(checkpoint_path, map_location=torch.device("cpu"))
WARNING:root:Detected old config, converting to new format. Consider updating to avoid potential incompatibilities.
INFO:root:amp: true
cmd:
checkpoint_dir: /home/runner/work/fairchem/fairchem/docs/core/checkpoints/2025-01-21-19-37-36
commit: c162617
identifier: ''
logs_dir: /home/runner/work/fairchem/fairchem/docs/core/logs/wandb/2025-01-21-19-37-36
print_every: 100
results_dir: /home/runner/work/fairchem/fairchem/docs/core/results/2025-01-21-19-37-36
seed: null
timestamp_id: 2025-01-21-19-37-36
version: 0.1.dev1+gc162617
dataset:
format: oc22_lmdb
key_mapping:
force: forces
y: energy
normalize_labels: false
oc20_ref: /checkpoint/janlan/ocp/other_data/final_ref_energies_02_07_2021.pkl
raw_energy_target: true
evaluation_metrics:
metrics:
energy:
- mae
forces:
- forcesx_mae
- forcesy_mae
- forcesz_mae
- mae
- cosine_similarity
- magnitude_error
misc:
- energy_forces_within_threshold
primary_metric: forces_mae
gp_gpus: null
gpus: 0
logger: wandb
loss_functions:
- energy:
coefficient: 1
fn: mae
- forces:
coefficient: 1
fn: l2mae
model:
activation: silu
atom_edge_interaction: true
atom_interaction: true
cbf:
name: spherical_harmonics
cutoff: 12.0
cutoff_aeaint: 12.0
cutoff_aint: 12.0
cutoff_qint: 12.0
direct_forces: true
edge_atom_interaction: true
emb_size_aint_in: 64
emb_size_aint_out: 64
emb_size_atom: 256
emb_size_cbf: 16
emb_size_edge: 512
emb_size_quad_in: 32
emb_size_quad_out: 32
emb_size_rbf: 16
emb_size_sbf: 32
emb_size_trip_in: 64
emb_size_trip_out: 64
envelope:
exponent: 5
name: polynomial
extensive: true
forces_coupled: false
max_neighbors: 30
max_neighbors_aeaint: 20
max_neighbors_aint: 1000
max_neighbors_qint: 8
name: gemnet_oc
num_after_skip: 2
num_atom: 3
num_atom_emb_layers: 2
num_before_skip: 2
num_blocks: 4
num_concat: 1
num_global_out_layers: 2
num_output_afteratom: 3
num_radial: 128
num_spherical: 7
otf_graph: true
output_init: HeOrthogonal
qint_tags:
- 1
- 2
quad_interaction: true
rbf:
name: gaussian
regress_forces: true
sbf:
name: legendre_outer
symmetric_edge_symmetrization: false
optim:
batch_size: 16
clip_grad_norm: 10
ema_decay: 0.999
energy_coefficient: 1
eval_batch_size: 16
eval_every: 5000
factor: 0.8
force_coefficient: 1
load_balancing: atoms
loss_energy: mae
loss_force: atomwisel2
lr_initial: 0.0005
max_epochs: 80
mode: min
num_workers: 2
optimizer: AdamW
optimizer_params:
amsgrad: true
patience: 3
scheduler: ReduceLROnPlateau
weight_decay: 0
outputs:
energy:
level: system
forces:
eval_on_free_atoms: true
level: atom
train_on_free_atoms: true
relax_dataset: {}
slurm:
additional_parameters:
constraint: volta32gb
cpus_per_task: 3
folder: /checkpoint/abhshkdz/ocp_oct1_logs/57632342
gpus_per_node: 8
job_id: '57632342'
job_name: gnoc_oc22_oc20_all_s2ef
mem: 480GB
nodes: 8
ntasks_per_node: 8
partition: ocp,learnaccel
time: 4320
task:
dataset: oc22_lmdb
description: Regressing to energies and forces for DFT trajectories from OCP
eval_on_free_atoms: true
grad_input: atomic forces
labels:
- potential energy
metric: mae
primary_metric: forces_mae
train_on_free_atoms: true
type: regression
test_dataset: {}
trainer: ocp
val_dataset: {}
INFO:root:Loading model: gemnet_oc
WARNING:root:Unrecognized arguments: ['symmetric_edge_symmetrization']
INFO:root:Loaded GemNetOC with 38864438 parameters.
INFO:root:Loading checkpoint in inference-only mode, not loading keys associated with trainer state!
INFO:root:Overwriting scaling factors with those loaded from checkpoint. If you're generating predictions with a pretrained checkpoint, this is the correct behavior. To disable this, delete `scale_dict` from the checkpoint.
WARNING:root:No seed has been set in modelcheckpoint or OCPCalculator! Results may not be reproducible on re-run
/tmp/ipykernel_3657/3462928393.py:13: FutureWarning: Please use atoms.calc = calc
slab.set_calculator(calc)
Step Time Energy fmax
BFGS: 0 19:38:13 -110.400406 1.627233
BFGS: 1 19:38:14 -110.542839 0.924819
BFGS: 2 19:38:14 -110.626541 0.568005
BFGS: 3 19:38:15 -110.605003 0.585444
BFGS: 4 19:38:15 -110.652641 0.443063
BFGS: 5 19:38:16 -110.698265 0.369424
BFGS: 6 19:38:16 -110.729652 0.604163
BFGS: 7 19:38:17 -110.766403 0.711393
BFGS: 8 19:38:17 -110.869637 0.512456
BFGS: 9 19:38:17 -110.945900 0.158336
BFGS: 10 19:38:18 -110.976570 0.086625
BFGS: 11 19:38:18 -110.992783 0.074964
BFGS: 12 19:38:19 -111.000832 0.063625
BFGS: 13 19:38:19 -111.000153 0.061604
BFGS: 14 19:38:20 -111.009369 0.058362
BFGS: 15 19:38:20 -111.015068 0.054439
BFGS: 16 19:38:21 -111.019554 0.033223
To learn more about what this simulation means and how it fits into catalysis, see the catalysis tutorial!