Fast batched inference#
The ASE calculator is not necessarily the most efficient way to run a lot of computations. It is better to do a “mass inference” using a command line utility. We illustrate how to do that here.
In this paper we computed about 10K different gold structures:
Boes, J. R., Groenenboom, M. C., Keith, J. A., & Kitchin, J. R. (2016). Neural network and Reaxff comparison for Au properties. Int. J. Quantum Chem., 116(13), 979–987. http://dx.doi.org/10.1002/qua.25115
You can retrieve the dataset below. In this notebook we learn how to do “mass inference” without an ASE calculator. You do this by creating a config.yml file, and running the main.py command line utility.
from fairchem.core.scripts.download_large_files import download_file_group
download_file_group('docs')
/home/runner/work/fairchem/fairchem/docs/tutorials/NRR/NRR_example_bulks.pkl already exists
/home/runner/work/fairchem/fairchem/docs/core/fine-tuning/supporting-information.json already exists
/home/runner/work/fairchem/fairchem/docs/core/data.db already exists
Inference on this file will be fast if we have a gpu, but if we don’t this could take a while. To keep things fast for the automated builds, we’ll just select the first 10 structures so it’s still approachable with just a CPU. Comment or skip this block to use the whole dataset!
! mv data.db full_data.db
import ase.db
import numpy as np
with ase.db.connect('full_data.db') as full_db:
with ase.db.connect('data.db',append=False) as subset_db:
# Select 50 random points for the subset, ASE DB ids start at 1
for i in np.random.choice(list(range(1,len(full_db)+1)),size=50,replace=False):
atoms = full_db.get_atoms(f'id={i}', add_additional_information=True)
if 'tag' in atoms.info['key_value_pairs']:
atoms.info['key_value_pairs']['tag'] = int(atoms.info['key_value_pairs']['tag'])
for key in atoms.info["key_value_pairs"]:
if atoms.info["key_value_pairs"][key] == "True":
atoms.info["key_value_pairs"][key] = True
elif atoms.info["key_value_pairs"][key] == "False":
atoms.info["key_value_pairs"][key] = False
subset_db.write(atoms, **atoms.info['key_value_pairs'])
! ase db data.db
id|age|user |formula|calculator| energy|natoms| fmax|pbc| volume|charge| mass
1| 0s|runner|Au12 |unknown | -27.014| 12|0.108|TTT|3571.095| 0.000| 2363.599
2| 0s|runner|Au2 |unknown | -2.919| 2|0.000|TTT| 24.813| 0.000| 393.933
3| 0s|runner|Au38 |unknown | -98.549| 38|0.088|TTT|5846.048| 0.000| 7484.730
4| 0s|runner|Au49 |unknown |-142.443| 49|0.040|TTT|2511.041| 0.000| 9651.362
5| 0s|runner|Au9 |unknown | -18.804| 9|0.415|TTT|3256.028| 0.000| 1772.699
6| 0s|runner|Au25 |unknown | -61.363| 25|0.254|TTT|4771.343| 0.000| 4924.164
7| 0s|runner|Au42 |unknown |-109.596| 42|0.302|TTT|6103.808| 0.000| 8272.596
8| 0s|runner|Au113 |vasp |-345.174| 113|0.240|TTT|9178.098| 0.000|22257.222
9| 0s|runner|Au29 |unknown | -72.861| 29|0.232|TTT|5184.740| 0.000| 5712.031
10| 0s|runner|Au35 |unknown | -90.657| 35|0.298|TTT|5504.869| 0.000| 6893.830
11| 0s|runner|Au34 |unknown | -74.577| 34|2.646|TTT|5583.053| 0.000| 6696.863
12| 0s|runner|Au53 |unknown |-136.412| 53|0.611|TTT|6796.009| 0.000|10439.228
13| 0s|runner|Au53 |unknown |-136.122| 53|0.566|TTT|6796.009| 0.000|10439.228
14| 0s|runner|Au13 |unknown | -27.468| 13|0.601|TTT|3635.026| 0.000| 2560.565
15| 0s|runner|Au4 |unknown | -11.812| 4|0.304|TTT| 156.940| 0.000| 787.866
16| 0s|runner|Au |unknown | -1.223| 1|0.000|TTT| 50.666| 0.000| 196.967
17| 0s|runner|Au14 |unknown | -31.173| 14|0.285|TTT|3847.524| 0.000| 2757.532
18| 0s|runner|Au13 |unknown | -28.072| 13|1.522|TTT|4419.768| 0.000| 2560.565
19| 0s|runner|Au38 |unknown | -98.003| 38|0.104|TTT|5846.048| 0.000| 7484.730
20| 0s|runner|Au4 |unknown | -12.200| 4|0.034|TTT| 143.096| 0.000| 787.866
Rows: 50 (showing first 20)
Keys: NEB, bulk, calc_time, cluster, config, diffusion, ediff, ediffg, encut, factor, fermi, fit, gga, group, identity, image, kpt1, kpt2, kpt3, miller, neural_energy, reax_energy, strain, structure, surf, tag, train_set, traj, vacuum, volume, xc
You have to choose a checkpoint to start with. The newer checkpoints may require too much memory for this environment.
from fairchem.core.models.model_registry import available_pretrained_models
print(available_pretrained_models)
('CGCNN-S2EF-OC20-200k', 'CGCNN-S2EF-OC20-2M', 'CGCNN-S2EF-OC20-20M', 'CGCNN-S2EF-OC20-All', 'DimeNet-S2EF-OC20-200k', 'DimeNet-S2EF-OC20-2M', 'SchNet-S2EF-OC20-200k', 'SchNet-S2EF-OC20-2M', 'SchNet-S2EF-OC20-20M', 'SchNet-S2EF-OC20-All', 'DimeNet++-S2EF-OC20-200k', 'DimeNet++-S2EF-OC20-2M', 'DimeNet++-S2EF-OC20-20M', 'DimeNet++-S2EF-OC20-All', 'SpinConv-S2EF-OC20-2M', 'SpinConv-S2EF-OC20-All', 'GemNet-dT-S2EF-OC20-2M', 'GemNet-dT-S2EF-OC20-All', 'PaiNN-S2EF-OC20-All', 'GemNet-OC-S2EF-OC20-2M', 'GemNet-OC-S2EF-OC20-All', 'GemNet-OC-S2EF-OC20-All+MD', 'GemNet-OC-Large-S2EF-OC20-All+MD', 'SCN-S2EF-OC20-2M', 'SCN-t4-b2-S2EF-OC20-2M', 'SCN-S2EF-OC20-All+MD', 'eSCN-L4-M2-Lay12-S2EF-OC20-2M', 'eSCN-L6-M2-Lay12-S2EF-OC20-2M', 'eSCN-L6-M2-Lay12-S2EF-OC20-All+MD', 'eSCN-L6-M3-Lay20-S2EF-OC20-All+MD', 'EquiformerV2-83M-S2EF-OC20-2M', 'EquiformerV2-31M-S2EF-OC20-All+MD', 'EquiformerV2-153M-S2EF-OC20-All+MD', 'SchNet-S2EF-force-only-OC20-All', 'DimeNet++-force-only-OC20-All', 'DimeNet++-Large-S2EF-force-only-OC20-All', 'DimeNet++-S2EF-force-only-OC20-20M+Rattled', 'DimeNet++-S2EF-force-only-OC20-20M+MD', 'CGCNN-IS2RE-OC20-10k', 'CGCNN-IS2RE-OC20-100k', 'CGCNN-IS2RE-OC20-All', 'DimeNet-IS2RE-OC20-10k', 'DimeNet-IS2RE-OC20-100k', 'DimeNet-IS2RE-OC20-all', 'SchNet-IS2RE-OC20-10k', 'SchNet-IS2RE-OC20-100k', 'SchNet-IS2RE-OC20-All', 'DimeNet++-IS2RE-OC20-10k', 'DimeNet++-IS2RE-OC20-100k', 'DimeNet++-IS2RE-OC20-All', 'PaiNN-IS2RE-OC20-All', 'GemNet-dT-S2EFS-OC22', 'GemNet-OC-S2EFS-OC22', 'GemNet-OC-S2EFS-OC20+OC22', 'GemNet-OC-S2EFS-nsn-OC20+OC22', 'GemNet-OC-S2EFS-OC20->OC22', 'EquiformerV2-lE4-lF100-S2EFS-OC22', 'SchNet-S2EF-ODAC', 'DimeNet++-S2EF-ODAC', 'PaiNN-S2EF-ODAC', 'GemNet-OC-S2EF-ODAC', 'eSCN-S2EF-ODAC', 'EquiformerV2-S2EF-ODAC', 'EquiformerV2-Large-S2EF-ODAC', 'Gemnet-OC-IS2RE-ODAC', 'eSCN-IS2RE-ODAC', 'EquiformerV2-IS2RE-ODAC', 'EquiformerV2-153M-OMAT24', 'EquiformerV2-153M-OMAT24-MP-sAlex', 'EquiformerV2-31M-MP', 'EquiformerV2-31M-OMAT24', 'EquiformerV2-31M-OMAT24-MP-sAlex', 'EquiformerV2-86M-OMAT24', 'EquiformerV2-86M-OMAT24-MP-sAlex', 'EquiformerV2-DeNS-153M-MP', 'EquiformerV2-DeNS-86M-MP', 'EquiformerV2-DeNS-31M-MP')
from fairchem.core.models.model_registry import model_name_to_local_file
checkpoint_path = model_name_to_local_file('GemNet-dT-S2EFS-OC22', local_cache='/tmp/fairchem_checkpoints/')
checkpoint_path
'/tmp/fairchem_checkpoints/gndt_oc22_all_s2ef.pt'
We have to update our configuration yml file with the test dataset.
from fairchem.core.common.tutorial_utils import generate_yml_config
yml = generate_yml_config(checkpoint_path, 'config.yml',
delete=['cmd', 'logger', 'task', 'model_attributes',
'dataset', 'slurm'],
update={'amp': True,
'gpus': 1,
'task.prediction_dtype': 'float32',
'logger':'tensorboard', # don't use wandb!
# Test data - prediction only so no regression
'dataset.test.src': 'data.db',
'dataset.test.format': 'ase_db',
'dataset.test.a2g_args.r_energy': False,
'dataset.test.a2g_args.r_forces': False,
'dataset.test.select_args.selection': 'natoms>5,xc=PBE',
})
yml
/home/runner/work/fairchem/fairchem/src/fairchem/core/models/scn/spherical_harmonics.py:23: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
_Jd = torch.load(os.path.join(os.path.dirname(__file__), "Jd.pt"))
/home/runner/work/fairchem/fairchem/src/fairchem/core/models/equiformer_v2/wigner.py:10: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
_Jd = torch.load(os.path.join(os.path.dirname(__file__), "Jd.pt"))
/home/runner/work/fairchem/fairchem/src/fairchem/core/models/escn/so3.py:23: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
_Jd = torch.load(os.path.join(os.path.dirname(__file__), "Jd.pt"))
/home/runner/work/fairchem/fairchem/src/fairchem/core/common/relaxation/ase_utils.py:200: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
checkpoint = torch.load(checkpoint_path, map_location=torch.device("cpu"))
WARNING:root:Detected old config, converting to new format. Consider updating to avoid potential incompatibilities.
INFO:root:amp: true
cmd:
checkpoint_dir: /home/runner/work/fairchem/fairchem/docs/core/checkpoints/2025-03-29-04-41-36
commit: core:b88b66e,experimental:NA
identifier: ''
logs_dir: /home/runner/work/fairchem/fairchem/docs/core/logs/wandb/2025-03-29-04-41-36
print_every: 100
results_dir: /home/runner/work/fairchem/fairchem/docs/core/results/2025-03-29-04-41-36
seed: null
timestamp_id: 2025-03-29-04-41-36
version: 0.1.dev1+gb88b66e
dataset:
format: oc22_lmdb
key_mapping:
force: forces
y: energy
normalize_labels: false
oc20_ref: /checkpoint/janlan/ocp/other_data/final_ref_energies_02_07_2021.pkl
raw_energy_target: true
evaluation_metrics:
metrics:
energy:
- mae
forces:
- forcesx_mae
- forcesy_mae
- forcesz_mae
- mae
- cosine_similarity
- magnitude_error
misc:
- energy_forces_within_threshold
primary_metric: forces_mae
gp_gpus: null
gpus: 0
logger: wandb
loss_functions:
- energy:
coefficient: 1
fn: mae
- forces:
coefficient: 1
fn: l2mae
model:
activation: silu
cbf:
name: spherical_harmonics
cutoff: 6.0
direct_forces: true
emb_size_atom: 512
emb_size_bil_trip: 64
emb_size_cbf: 16
emb_size_edge: 512
emb_size_rbf: 16
emb_size_trip: 64
envelope:
exponent: 5
name: polynomial
extensive: true
max_neighbors: 50
name: gemnet_t
num_after_skip: 2
num_atom: 3
num_before_skip: 1
num_blocks: 3
num_concat: 1
num_radial: 128
num_spherical: 7
otf_graph: true
output_init: HeOrthogonal
rbf:
name: gaussian
regress_forces: true
optim:
batch_size: 16
clip_grad_norm: 10
ema_decay: 0.999
energy_coefficient: 1
eval_batch_size: 16
eval_every: 5000
force_coefficient: 1
loss_energy: mae
loss_force: atomwisel2
lr_gamma: 0.8
lr_initial: 0.0005
lr_milestones:
- 64000
- 96000
- 128000
- 160000
- 192000
max_epochs: 80
num_workers: 2
optimizer: AdamW
optimizer_params:
amsgrad: true
warmup_steps: -1
outputs:
energy:
level: system
forces:
eval_on_free_atoms: true
level: atom
train_on_free_atoms: true
relax_dataset: {}
slurm:
additional_parameters:
constraint: volta32gb
cpus_per_task: 3
folder: /checkpoint/abhshkdz/ocp_oct1_logs/57864354
gpus_per_node: 8
job_id: '57864354'
job_name: gndt_oc22_s2ef
mem: 480GB
nodes: 2
ntasks_per_node: 8
partition: ocp
time: 4320
task:
dataset: oc22_lmdb
eval_on_free_atoms: true
primary_metric: forces_mae
train_on_free_atoms: true
test_dataset: {}
trainer: ocp
val_dataset: {}
INFO:root:Loading model: gemnet_t
INFO:root:Loaded GemNetT with 31671825 parameters.
INFO:root:Loading checkpoint in inference-only mode, not loading keys associated with trainer state!
INFO:root:Overwriting scaling factors with those loaded from checkpoint. If you're generating predictions with a pretrained checkpoint, this is the correct behavior. To disable this, delete `scale_dict` from the checkpoint.
WARNING:root:Scale factor comment not found in model
WARNING:root:No seed has been set in modelcheckpoint or OCPCalculator! Results may not be reproducible on re-run
PosixPath('/home/runner/work/fairchem/fairchem/docs/core/config.yml')
It is a good idea to redirect the output to a file. If the output gets too large here, the notebook may fail to save. Normally I would use a redirect like 2&>1, but this does not work with the main.py method. An alternative here is to open a terminal and run it there. If you have a gpu or multiple gpus, you should use the flag –num-gpus=
%%capture inference
import time
from fairchem.core.common.tutorial_utils import fairchem_main
t0 = time.time()
! python {fairchem_main()} --mode predict --config-yml {yml} --checkpoint {checkpoint_path} --cpu
print(f'Elapsed time = {time.time() - t0:1.1f} seconds')
with open('mass-inference.txt', 'wb') as f:
f.write(inference.stdout.encode('utf-8'))
! grep "Total time taken:" 'mass-inference.txt'
2025-03-29 04:42:03 /home/runner/work/fairchem/fairchem/src/fairchem/core/common/utils.py:1113: (INFO): Total time taken: 8.011998176574707
The mass inference approach takes 1-2 minutes to run. See the output here.
results = ! grep " results_dir:" mass-inference.txt
d = results[0].split(':')[-1].strip()
import numpy as np
results = np.load(f'{d}/ocp_predictions.npz', allow_pickle=True)
results.files
['energy', 'forces', 'chunk_idx', 'ids']
It is not obvious, but the data from mass inference is not in the same order. We have to get an id from the mass inference, and then “resort” the results so they are in the same order.
inds = np.array([int(r.split('_')[0]) for r in results['ids']])
sind = np.argsort(inds)
inds[sind]
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37])
To compare this with the results, we need to get the energy data from the ase db.
from ase.db import connect
db = connect('data.db')
energies = np.array([row.energy for row in db.select('natoms>5,xc=PBE')])
natoms = np.array([row.natoms for row in db.select('natoms>5,xc=PBE')])
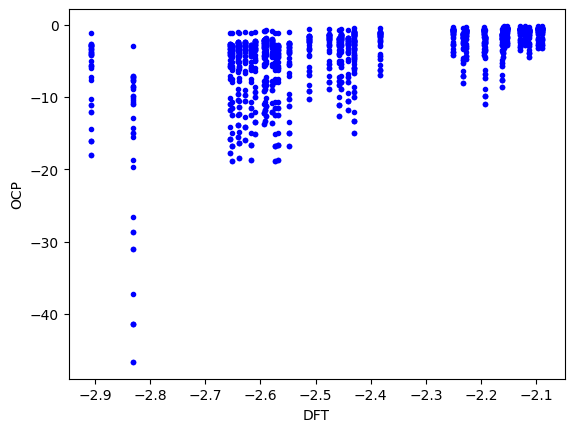
Now, we can see the predictions. They are only ok here; that is not surprising, the data set has lots of Au configurations that have never been seen by this model. Fine-tuning would certainly help improve this.
import matplotlib.pyplot as plt
plt.plot(energies / natoms, results['energy'][sind] / natoms, 'b.')
plt.xlabel('DFT')
plt.ylabel('OCP');
The ASE calculator way#
We include this here just to show that:
We get the same results
That this is much slower.
from fairchem.core.common.relaxation.ase_utils import OCPCalculator
calc = OCPCalculator(checkpoint_path=checkpoint_path, cpu=False)
/home/runner/work/fairchem/fairchem/src/fairchem/core/common/relaxation/ase_utils.py:200: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
checkpoint = torch.load(checkpoint_path, map_location=torch.device("cpu"))
WARNING:root:Detected old config, converting to new format. Consider updating to avoid potential incompatibilities.
INFO:root:amp: true
cmd:
checkpoint_dir: /home/runner/work/fairchem/fairchem/docs/core/checkpoints/2025-03-29-04-41-36
commit: core:b88b66e,experimental:NA
identifier: ''
logs_dir: /home/runner/work/fairchem/fairchem/docs/core/logs/wandb/2025-03-29-04-41-36
print_every: 100
results_dir: /home/runner/work/fairchem/fairchem/docs/core/results/2025-03-29-04-41-36
seed: null
timestamp_id: 2025-03-29-04-41-36
version: 0.1.dev1+gb88b66e
dataset:
format: oc22_lmdb
key_mapping:
force: forces
y: energy
normalize_labels: false
oc20_ref: /checkpoint/janlan/ocp/other_data/final_ref_energies_02_07_2021.pkl
raw_energy_target: true
evaluation_metrics:
metrics:
energy:
- mae
forces:
- forcesx_mae
- forcesy_mae
- forcesz_mae
- mae
- cosine_similarity
- magnitude_error
misc:
- energy_forces_within_threshold
primary_metric: forces_mae
gp_gpus: null
gpus: 0
logger: wandb
loss_functions:
- energy:
coefficient: 1
fn: mae
- forces:
coefficient: 1
fn: l2mae
model:
activation: silu
cbf:
name: spherical_harmonics
cutoff: 6.0
direct_forces: true
emb_size_atom: 512
emb_size_bil_trip: 64
emb_size_cbf: 16
emb_size_edge: 512
emb_size_rbf: 16
emb_size_trip: 64
envelope:
exponent: 5
name: polynomial
extensive: true
max_neighbors: 50
name: gemnet_t
num_after_skip: 2
num_atom: 3
num_before_skip: 1
num_blocks: 3
num_concat: 1
num_radial: 128
num_spherical: 7
otf_graph: true
output_init: HeOrthogonal
rbf:
name: gaussian
regress_forces: true
optim:
batch_size: 16
clip_grad_norm: 10
ema_decay: 0.999
energy_coefficient: 1
eval_batch_size: 16
eval_every: 5000
force_coefficient: 1
loss_energy: mae
loss_force: atomwisel2
lr_gamma: 0.8
lr_initial: 0.0005
lr_milestones:
- 64000
- 96000
- 128000
- 160000
- 192000
max_epochs: 80
num_workers: 2
optimizer: AdamW
optimizer_params:
amsgrad: true
warmup_steps: -1
outputs:
energy:
level: system
forces:
eval_on_free_atoms: true
level: atom
train_on_free_atoms: true
relax_dataset: {}
slurm:
additional_parameters:
constraint: volta32gb
cpus_per_task: 3
folder: /checkpoint/abhshkdz/ocp_oct1_logs/57864354
gpus_per_node: 8
job_id: '57864354'
job_name: gndt_oc22_s2ef
mem: 480GB
nodes: 2
ntasks_per_node: 8
partition: ocp
time: 4320
task:
dataset: oc22_lmdb
eval_on_free_atoms: true
primary_metric: forces_mae
train_on_free_atoms: true
test_dataset: {}
trainer: ocp
val_dataset: {}
INFO:root:Loading model: gemnet_t
INFO:root:Loaded GemNetT with 31671825 parameters.
INFO:root:Loading checkpoint in inference-only mode, not loading keys associated with trainer state!
INFO:root:Overwriting scaling factors with those loaded from checkpoint. If you're generating predictions with a pretrained checkpoint, this is the correct behavior. To disable this, delete `scale_dict` from the checkpoint.
WARNING:root:Scale factor comment not found in model
WARNING:root:No seed has been set in modelcheckpoint or OCPCalculator! Results may not be reproducible on re-run
import time
from tqdm import tqdm
t0 = time.time()
OCP, DFT = [], []
for row in tqdm(db.select('natoms>5,xc=PBE')):
atoms = row.toatoms()
atoms.set_calculator(calc)
DFT += [row.energy / len(atoms)]
OCP += [atoms.get_potential_energy() / len(atoms)]
print(f'Elapsed time {time.time() - t0:1.1} seconds')
0it [00:00, ?it/s]
/tmp/ipykernel_3700/402181013.py:7: FutureWarning: Please use atoms.calc = calc
atoms.set_calculator(calc)
1it [00:00, 6.93it/s]
2it [00:00, 3.69it/s]
3it [00:01, 2.44it/s]
4it [00:01, 3.48it/s]
5it [00:01, 4.00it/s]
6it [00:01, 3.50it/s]
7it [00:01, 3.58it/s]
8it [00:02, 3.79it/s]
9it [00:02, 4.14it/s]
10it [00:02, 3.48it/s]
11it [00:03, 3.12it/s]
12it [00:03, 3.84it/s]
13it [00:03, 4.64it/s]
14it [00:03, 4.97it/s]
15it [00:03, 4.57it/s]
17it [00:04, 5.35it/s]
18it [00:04, 4.37it/s]
20it [00:04, 5.56it/s]
22it [00:05, 5.90it/s]
23it [00:05, 4.55it/s]
24it [00:05, 4.61it/s]
26it [00:05, 5.81it/s]
27it [00:07, 2.43it/s]
28it [00:07, 2.49it/s]
29it [00:07, 2.81it/s]
30it [00:08, 2.84it/s]
31it [00:08, 3.06it/s]
32it [00:08, 2.99it/s]
33it [00:08, 3.14it/s]
34it [00:09, 3.66it/s]
35it [00:09, 3.47it/s]
36it [00:09, 3.64it/s]
37it [00:09, 4.45it/s]
38it [00:10, 3.52it/s]
38it [00:10, 3.72it/s]
Elapsed time 1e+01 seconds
This takes at least twice as long as the mass-inference approach above. It is conceptually simpler though, and does not require resorting.
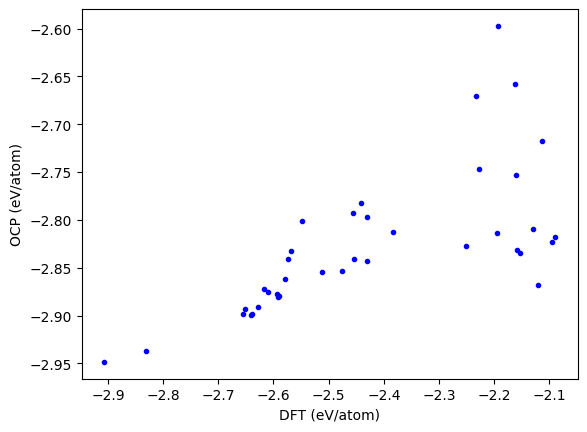
plt.plot(DFT, OCP, 'b.')
plt.xlabel('DFT (eV/atom)')
plt.ylabel('OCP (eV/atom)');
Comparing ASE calculator and main.py#
The results should be the same.
It is worth noting the default precision of predictions is float16 with main.py, but with the ASE calculator the default precision is float32. Supposedly you can specify --task.prediction_dtype=float32 at the command line to or specify it in the config.yml like we do above, but as of the tutorial this does not resolve the issue.
As noted above (see also Issue 542), the ASE calculator and main.py use different precisions by default, which can lead to small differences.
np.mean(np.abs(results['energy'][sind] - OCP * natoms)) # MAE
63.61125500644673
np.min(results['energy'][sind] - OCP * natoms), np.max(results['energy'][sind] - OCP * natoms)
(-350.2818775177002, 350.2818775177002)
plt.hist(results['energy'][sind] - OCP * natoms, bins=20);
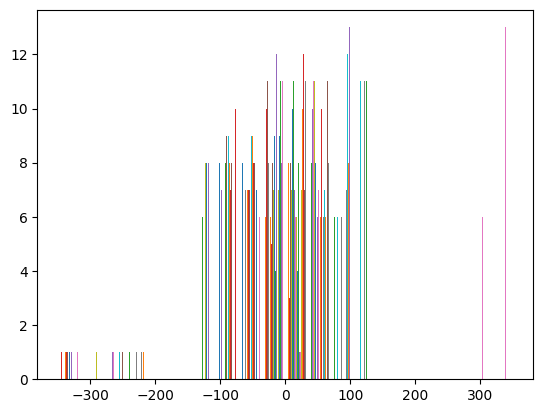
Here we see many of the differences are very small. 0.0078125 = 1 / 128, and these errors strongly suggest some kind of mixed precision is responsible for these differences. It is an open issue to remove them and identify where the cause is.
(results['energy'][sind] - OCP * natoms)[0:400]
array([[ 0. , 75.42024612, 110.54531479, ..., 60.68180466,
-10.98033524, 116.49222946],
[ -75.42024612, 0. , 35.12506866, ..., -14.73844147,
-86.40058136, 41.07198334],
[-110.54531479, -35.12506866, 0. , ..., -49.86351013,
-121.52565002, 5.94691467],
...,
[ -60.68180466, 14.73844147, 49.86351013, ..., 0. ,
-71.66213989, 55.8104248 ],
[ 10.98033524, 86.40058136, 121.52565002, ..., 71.66213989,
0. , 127.4725647 ],
[-116.49222946, -41.07198334, -5.94691467, ..., -55.8104248 ,
-127.4725647 , 0. ]])